Generated April 27, 2022
The publication may not be available at the time of the static Narrative creation. This can be added after the fact; please contact [email protected] to update the DOI landing page when this is done.
from biokbase.narrative.jobs.appmanager import AppManager
AppManager().run_app_bulk(
[{
"app_id": "kb_uploadmethods/import_fasta_as_assembly_from_staging",
"tag": "release",
"version": "1dbd08a56befada8f204b4d1db5a872796cd45a5",
"params": [{
"staging_file_subdir_path": "Barcode05.fasta",
"assembly_name": "Barcode05.fasta_assembly",
"type": "draft isolate",
"min_contig_length": 10000
}]
}],
cell_id="61e87ea3-aab8-4209-86fa-5356051cf780",
run_id="d9da3558-3ae8-402c-970b-dca0dcfcebc2"
)

| Created Object Name | Type | Description |
|---|---|---|
| Barcode05.fasta_assembly_DRAM | Genome | Annotated Genome |
| Ensifer | GenomeSet | Ensifer genome? |


| Created Object Name | Type | Description |
|---|---|---|
| RAST-annotation | Genome | RAST re-annotated genome |

| Created Object Name | Type | Description |
|---|---|---|
| Prokka-ann | Genome | Annotated Genome |
| Created Object Name | Type | Description |
|---|---|---|
| Barcode05.fasta_assembly_DRAM | Genome | Taxonomy and taxon_assignment updated with GTDB |
| Ensifer | GenomeSet | Taxonomy and taxon_assignment updated with GTDB |

| Barcode05.fasta_assembly_DRAM |

Annotate Assembly and Re-annotate Genomes with Prokka - v1.14.5
Annotate Genome/Assembly with RASTtk - v1.073
Assess Read Quality with FastQC - v0.11.9
Classify Microbes with GTDB-Tk - v1.7.0
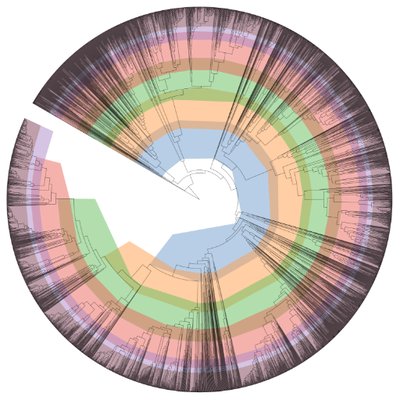
Insert Genome Into SpeciesTree - v2.2.0
Upload File to Staging from Web - v1.0.12
v1 - KBaseGenomeAnnotations.Assembly-5.0