Generated September 14, 2022
Upon investigating the gut microbiome of mice for microbes related to Polycystic Ovary Syndrome (PCOS), our team found 2 metagenomes that could not be classified using alignment based methods. To further investigate microbial species from these samples, we used common MAGs workflow to create draft genomes which were then later taxonomically classified using GTDB-tk app.
from biokbase.narrative.jobs.appmanager import AppManager
AppManager().run_app_batch(
[{
"app_id": "kb_uploadmethods/import_fasta_as_assembly_from_staging",
"tag": "release",
"version": "d67ff71a675aed5566d257c267689ea0d2a4a8b0",
"params": [{
"staging_file_subdir_path": "scaffolds.fasta",
"assembly_name": "scaffolds.fasta_assembly"
}],
"shared_params": {
"type": "draft isolate",
"min_contig_length": 500
}
}, {
"app_id": "kb_uploadmethods/import_fastq_noninterleaved_as_reads_from_staging",
"tag": "release",
"version": "d67ff71a675aed5566d257c267689ea0d2a4a8b0",
"params": [{
"fastq_fwd_staging_file_name": "mouse_132_T4_S87_L001_R1_001.fastq.gz",
"fastq_rev_staging_file_name": "mouse_132_T4_S87_L001_R2_001.fastq.gz",
"name": "mouse_132"
}, {
"fastq_fwd_staging_file_name": "mouse_112_T4_S86_L001_R1_001.fastq.gz",
"fastq_rev_staging_file_name": "mouse_112_T4_S86_L001_R2_001.fastq.gz",
"name": "mouse_112"
}],
"shared_params": {
"sequencing_tech": "Illumina",
"single_genome": 1,
"read_orientation_outward": 0,
"insert_size_std_dev": None,
"insert_size_mean": None
}
}],
cell_id="e7f10ab6-212f-4b49-b542-fed7f2700d3f",
run_id="7aef9407-2a90-4ba9-8a1e-200eff598ba2"
)
The reassembly of metagenomes were conducted outside of kbase using SPAdes software. To bin the contigs we used MaxBin2 and to refine the bins produced from Maxbin2 we used DASTool. The reason we decided to refine the bins, was to get higher quality draft genomes and remove any dubplicate contigs in each bin.

| mouse_132 |
| mouse_112 |
| Created Object Name | Type | Description |
|---|---|---|
| mouse_scaffolds_binned_MaxBin2 | BinnedContigs | BinnedContigs from MaxBin2 |

| mouse_scaffolds_binned_MaxBin2 |
After binning process, we annotated our bins using RASTtk. Annotations were then later used to determine if each bin contained the essential components for a living organism.

| extracted_bins.AssemblySet |
The RAST algorithm was applied to annotating a genome sequence comprised of 131 contigs containing 3071452 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3022 new features were called, of which 136 are non-coding. Output genome has the following feature types: Coding gene 2886 Non-coding crispr_array 1 Non-coding crispr_repeat 17 Non-coding crispr_spacer 16 Non-coding repeat 50 Non-coding rna 52 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.016.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 103 contigs containing 2829289 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3188 new features were called, of which 52 are non-coding. Output genome has the following feature types: Coding gene 3136 Non-coding repeat 24 Non-coding rna 28 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.051.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 122 contigs containing 2333177 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2514 new features were called, of which 259 are non-coding. Output genome has the following feature types: Coding gene 2255 Non-coding crispr_array 1 Non-coding crispr_repeat 68 Non-coding crispr_spacer 67 Non-coding repeat 88 Non-coding rna 35 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.007.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 142 contigs containing 1554166 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1764 new features were called, of which 53 are non-coding. Output genome has the following feature types: Coding gene 1711 Non-coding repeat 23 Non-coding rna 30 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.046.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 132 contigs containing 3179658 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2839 new features were called, of which 57 are non-coding. Output genome has the following feature types: Coding gene 2782 Non-coding repeat 19 Non-coding rna 38 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.037.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 432 contigs containing 4637941 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 5183 new features were called, of which 131 are non-coding. Output genome has the following feature types: Coding gene 5052 Non-coding repeat 99 Non-coding rna 32 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.015.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 272 contigs containing 4495861 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 4958 new features were called, of which 277 are non-coding. Output genome has the following feature types: Coding gene 4681 Non-coding crispr_array 2 Non-coding crispr_repeat 83 Non-coding crispr_spacer 81 Non-coding repeat 73 Non-coding rna 38 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.019.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 256 contigs containing 3073907 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3518 new features were called, of which 79 are non-coding. Output genome has the following feature types: Coding gene 3439 Non-coding crispr_array 2 Non-coding crispr_repeat 25 Non-coding crispr_spacer 23 Non-coding repeat 11 Non-coding rna 18 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.022.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 572 contigs containing 1151330 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1958 new features were called, of which 10 are non-coding. Output genome has the following feature types: Coding gene 1948 Non-coding repeat 2 Non-coding rna 8 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.047.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 47 contigs containing 1845997 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1651 new features were called, of which 19 are non-coding. Output genome has the following feature types: Coding gene 1632 Non-coding repeat 2 Non-coding rna 17 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.042.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 254 contigs containing 3482378 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3810 new features were called, of which 204 are non-coding. Output genome has the following feature types: Coding gene 3606 Non-coding crispr_array 5 Non-coding crispr_repeat 54 Non-coding crispr_spacer 49 Non-coding repeat 66 Non-coding rna 30 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.024.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 33 contigs containing 1786607 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1830 new features were called, of which 128 are non-coding. Output genome has the following feature types: Coding gene 1702 Non-coding crispr_array 2 Non-coding crispr_repeat 23 Non-coding crispr_spacer 21 Non-coding repeat 43 Non-coding rna 39 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.005.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 52 contigs containing 1861431 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1946 new features were called, of which 103 are non-coding. Output genome has the following feature types: Coding gene 1843 Non-coding crispr_array 1 Non-coding crispr_repeat 13 Non-coding crispr_spacer 12 Non-coding repeat 44 Non-coding rna 33 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.025.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 113 contigs containing 2213058 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2430 new features were called, of which 130 are non-coding. Output genome has the following feature types: Coding gene 2300 Non-coding crispr_array 2 Non-coding crispr_repeat 24 Non-coding crispr_spacer 22 Non-coding repeat 45 Non-coding rna 37 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.006.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 41 contigs containing 2060480 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1980 new features were called, of which 59 are non-coding. Output genome has the following feature types: Coding gene 1921 Non-coding repeat 12 Non-coding rna 47 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.028.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 81 contigs containing 2706857 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2367 new features were called, of which 65 are non-coding. Output genome has the following feature types: Coding gene 2302 Non-coding repeat 19 Non-coding rna 46 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.017.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 481 contigs containing 1747970 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2528 new features were called, of which 58 are non-coding. Output genome has the following feature types: Coding gene 2470 Non-coding crispr_array 1 Non-coding crispr_repeat 16 Non-coding crispr_spacer 15 Non-coding repeat 2 Non-coding rna 24 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.032.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 64 contigs containing 1976154 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1744 new features were called, of which 40 are non-coding. Output genome has the following feature types: Coding gene 1704 Non-coding repeat 11 Non-coding rna 29 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.044.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 163 contigs containing 5219781 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 5035 new features were called, of which 154 are non-coding. Output genome has the following feature types: Coding gene 4881 Non-coding crispr_array 1 Non-coding crispr_repeat 10 Non-coding crispr_spacer 9 Non-coding repeat 67 Non-coding rna 67 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.030.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 74 contigs containing 3247437 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3820 new features were called, of which 66 are non-coding. Output genome has the following feature types: Coding gene 3754 Non-coding repeat 29 Non-coding rna 37 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.010.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 91 contigs containing 1828498 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2121 new features were called, of which 168 are non-coding. Output genome has the following feature types: Coding gene 1953 Non-coding crispr_array 2 Non-coding crispr_repeat 32 Non-coding crispr_spacer 30 Non-coding repeat 60 Non-coding rna 44 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.012.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 59 contigs containing 1955743 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1746 new features were called, of which 80 are non-coding. Output genome has the following feature types: Coding gene 1666 Non-coding crispr_array 1 Non-coding crispr_repeat 9 Non-coding crispr_spacer 8 Non-coding repeat 40 Non-coding rna 22 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.021.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 72 contigs containing 1524270 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1398 new features were called, of which 43 are non-coding. Output genome has the following feature types: Coding gene 1355 Non-coding repeat 21 Non-coding rna 22 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.023.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 751 contigs containing 5956186 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 7107 new features were called, of which 464 are non-coding. Output genome has the following feature types: Coding gene 6643 Non-coding crispr_array 2 Non-coding crispr_repeat 25 Non-coding crispr_spacer 23 Non-coding repeat 379 Non-coding rna 35 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.008.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 245 contigs containing 1103659 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1273 new features were called, of which 28 are non-coding. Output genome has the following feature types: Coding gene 1245 Non-coding repeat 17 Non-coding rna 11 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.001.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 21 contigs containing 1606372 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1734 new features were called, of which 53 are non-coding. Output genome has the following feature types: Coding gene 1681 Non-coding repeat 23 Non-coding rna 30 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.050.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 56 contigs containing 1915398 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1850 new features were called, of which 61 are non-coding. Output genome has the following feature types: Coding gene 1789 Non-coding repeat 23 Non-coding rna 38 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.035.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 62 contigs containing 2144203 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2286 new features were called, of which 69 are non-coding. Output genome has the following feature types: Coding gene 2217 Non-coding repeat 22 Non-coding rna 47 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.038.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 390 contigs containing 2309802 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2678 new features were called, of which 80 are non-coding. Output genome has the following feature types: Coding gene 2598 Non-coding repeat 44 Non-coding rna 36 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.011.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 251 contigs containing 4383635 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 4258 new features were called, of which 49 are non-coding. Output genome has the following feature types: Coding gene 4209 Non-coding repeat 14 Non-coding rna 35 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.002.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 219 contigs containing 3771889 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3730 new features were called, of which 76 are non-coding. Output genome has the following feature types: Coding gene 3654 Non-coding repeat 29 Non-coding rna 47 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.039.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 96 contigs containing 2680722 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2607 new features were called, of which 141 are non-coding. Output genome has the following feature types: Coding gene 2466 Non-coding crispr_array 1 Non-coding crispr_repeat 28 Non-coding crispr_spacer 27 Non-coding repeat 36 Non-coding rna 49 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.034.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 60 contigs containing 1836713 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1549 new features were called, of which 58 are non-coding. Output genome has the following feature types: Coding gene 1491 Non-coding crispr_array 1 Non-coding crispr_repeat 14 Non-coding crispr_spacer 13 Non-coding repeat 11 Non-coding rna 19 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.018.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 630 contigs containing 4109606 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 5389 new features were called, of which 175 are non-coding. Output genome has the following feature types: Coding gene 5214 Non-coding crispr_array 2 Non-coding crispr_repeat 24 Non-coding crispr_spacer 22 Non-coding repeat 79 Non-coding rna 48 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.004.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 339 contigs containing 2990041 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3355 new features were called, of which 48 are non-coding. Output genome has the following feature types: Coding gene 3307 Non-coding repeat 32 Non-coding rna 16 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.031.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 102 contigs containing 2078219 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1935 new features were called, of which 63 are non-coding. Output genome has the following feature types: Coding gene 1872 Non-coding repeat 41 Non-coding rna 22 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.040.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 214 contigs containing 4222813 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 4868 new features were called, of which 633 are non-coding. Output genome has the following feature types: Coding gene 4235 Non-coding crispr_array 6 Non-coding crispr_repeat 85 Non-coding crispr_spacer 79 Non-coding repeat 433 Non-coding rna 30 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.048.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 158 contigs containing 2068718 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2030 new features were called, of which 171 are non-coding. Output genome has the following feature types: Coding gene 1859 Non-coding repeat 132 Non-coding rna 39 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.009.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 492 contigs containing 2731838 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3044 new features were called, of which 57 are non-coding. Output genome has the following feature types: Coding gene 2987 Non-coding repeat 14 Non-coding rna 43 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.029.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 224 contigs containing 3420041 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3630 new features were called, of which 91 are non-coding. Output genome has the following feature types: Coding gene 3539 Non-coding repeat 45 Non-coding rna 46 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.033.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 98 contigs containing 2588322 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2285 new features were called, of which 49 are non-coding. Output genome has the following feature types: Coding gene 2236 Non-coding repeat 12 Non-coding rna 37 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.043.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 120 contigs containing 3023207 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2494 new features were called, of which 70 are non-coding. Output genome has the following feature types: Coding gene 2424 Non-coding repeat 50 Non-coding rna 20 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.003.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 610 contigs containing 4402949 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 4845 new features were called, of which 85 are non-coding. Output genome has the following feature types: Coding gene 4760 Non-coding repeat 59 Non-coding rna 26 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.026.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 194 contigs containing 3585436 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3806 new features were called, of which 107 are non-coding. Output genome has the following feature types: Coding gene 3699 Non-coding crispr_array 1 Non-coding crispr_repeat 10 Non-coding crispr_spacer 9 Non-coding repeat 56 Non-coding rna 31 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.014.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 96 contigs containing 2902469 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 3005 new features were called, of which 52 are non-coding. Output genome has the following feature types: Coding gene 2953 Non-coding crispr_array 1 Non-coding crispr_repeat 6 Non-coding crispr_spacer 5 Non-coding repeat 24 Non-coding rna 16 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.013.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 29 contigs containing 1581972 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 1313 new features were called, of which 29 are non-coding. Output genome has the following feature types: Coding gene 1284 Non-coding repeat 6 Non-coding rna 23 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.020.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 20 contigs containing 2146755 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2076 new features were called, of which 106 are non-coding. Output genome has the following feature types: Coding gene 1970 Non-coding crispr_array 1 Non-coding crispr_repeat 24 Non-coding crispr_spacer 23 Non-coding repeat 15 Non-coding rna 43 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.049.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 580 contigs containing 5555699 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 6363 new features were called, of which 377 are non-coding. Output genome has the following feature types: Coding gene 5986 Non-coding crispr_array 1 Non-coding crispr_repeat 24 Non-coding crispr_spacer 23 Non-coding repeat 295 Non-coding rna 34 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.041.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 126 contigs containing 3972461 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 4056 new features were called, of which 145 are non-coding. Output genome has the following feature types: Coding gene 3911 Non-coding crispr_array 2 Non-coding crispr_repeat 33 Non-coding crispr_spacer 31 Non-coding repeat 41 Non-coding rna 38 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.045.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 135 contigs containing 2385651 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2709 new features were called, of which 67 are non-coding. Output genome has the following feature types: Coding gene 2642 Non-coding crispr_array 1 Non-coding crispr_repeat 3 Non-coding crispr_spacer 2 Non-coding repeat 22 Non-coding rna 39 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.027.fasta_assembly succeeded! The RAST algorithm was applied to annotating a genome sequence comprised of 108 contigs containing 2917673 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 2617 new features were called, of which 133 are non-coding. Output genome has the following feature types: Coding gene 2484 Non-coding repeat 101 Non-coding rna 32 Overall, the genes have 0 distinct functions. The genes include 0 genes with a SEED annotation ontology across 0 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. bin.036.fasta_assembly succeeded!
To determine which bins are related to each other we inserted the annotated bins into a phylogenetic tree. KBase also looks at the annotations and compares bins to their own database, if a bin matches a genome that is already classified they insert that organism into the tree to show how well the bins relate to that taxonomically classified organism


| Created Object Name | Type | Description |
|---|---|---|
| extracted_bins.AssemblySet | AssemblySet | Assembly set of extracted assemblies |
| bin.038.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.007.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.035.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.051.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.050.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.016.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.029.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.044.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.014.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.032.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.026.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.017.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.003.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.028.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.043.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.006.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.033.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.002.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.019.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.034.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.047.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.004.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.024.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.040.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.005.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.048.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.025.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.020.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.012.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.041.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.023.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.027.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.008.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.036.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.001.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.046.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.011.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.037.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.039.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.015.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.018.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.022.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.031.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.042.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.009.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.030.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.013.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.010.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.049.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.021.fasta_assembly | Assembly | Assembly object of extracted contigs |
| bin.045.fasta_assembly | Assembly | Assembly object of extracted contigs |
The taxonomic classification was done using GTDB app. As we can see there are many bins that were not able to be completely classified. There also bins that seem to not have any close relavent taxonomic classes (i.e GTDB does not know what these bins are) and only show the lowest taxon level based on protein markers of contigs found in the annotated bins.
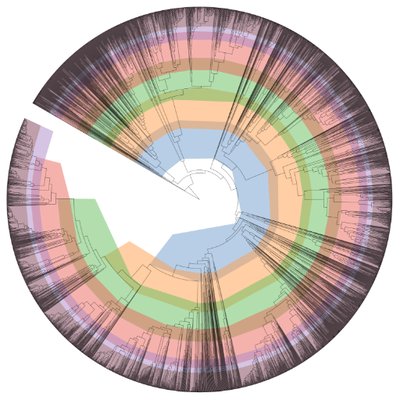
To determine the quality of our draft genomes we used CheckM. The results from CheckM and GTDBtk app where then used to do further analysis on a select few (n=5) genomes. The process of picking these genomes were discussed among researchers, and criteria that we used were CheckM completeness, FastANI, and frequency of contigs seen in metagenome (This analysis was done using Salmon).

After selecting five binned assemblys, we checked each bin to determine if they contained the necessary metabolic components to sustain living organisms. To do this we used DRAM, which gives us a visual representation of which metabolic pathways and enzymes in those pathways are present in our bins. To visualize the annotated bins we used circular genome visualization tool, which shows which regions on the contigs are CDS, GC skew, etc.....

| Created Object Name | Type | Description |
|---|---|---|
| bin.049.fasta_assembly_DRAM | Genome | Annotated Genome |
| Alistipes_Draft_Genome | GenomeSet | bin_049_Alistipes |
Special thanks to Alex Handzel for choosing the samples to run the analysis and Laura Sisk-Hackworth for DNA prep of metagenomes. Funding for the project was through NIH grant.