Generated December 10, 2024
Elisha J. Redman and Joshua T. Cooper ORCID
Department of Biological Sciences, Northern Kentucky University, 1 Nunn Drive, Highland Heights, KY 41099, USA
Exiguobacterium indicum has often reported from a wide variety of environmental samples, ranging from extreme to common habitats1,2. Here we report the 3.1-Mb draft genome of E. indicum strain LL15, discovered during an investigation of freshwater lakes in residential-urban environments.
The publication may not be available at the time of the static Narrative creation. This can be added after the fact; please contact [email protected] to update the DOI landing page when this is done.
from biokbase.narrative.jobs.appmanager import AppManager
AppManager().run_app_bulk(
[{
"app_id": "kb_uploadmethods/import_fastq_noninterleaved_as_reads_from_staging",
"tag": "release",
"version": "31e93066beb421a51b9c8e44b1201aa93aea0b4e",
"params": [{
"fastq_fwd_staging_file_name": "LL15_S182_R1_001.fastq.gz",
"fastq_rev_staging_file_name": "LL15_S182_R2_001.fastq.gz",
"name": "LL15reads",
"sequencing_tech": "Illumina",
"single_genome": 1,
"read_orientation_outward": 0,
"insert_size_std_dev": None,
"insert_size_mean": None
}]
}],
cell_id="25ece73e-368d-46da-90ef-3fa85fffcf88",
run_id="d3c5920f-acd6-4914-820f-d39065521349"
)
Raw data were processed using the KBase v2.3.2 web interface from quality control to genome assembly using default settings unless otherwise noted. Reads were quality controlled using FastQC v0.119, and then trimmed with Trimmomatic v0.36 and Nextera Adapters.
The genome was assembled using SPAdes v3.15.3 , a de Bruijn graph assembler into 10 contigs, with a total length of 3,102,801 bp, and an N50 of 2,120,415 bp. CheckM v1.0.18 was used to estimate the genome completeness and contamination. The genome of species LL15 was 99.34% complete and had 0.0% contamination.
Proteins were initially predicted using RASTtk v1.073 and Prokka v1.14.5. NCBI Prokaryotic Genome Annotation8 was used to make the final protein predictions to be compliant with GenBank submission.


| Created Object Name | Type | Description |
|---|---|---|
| LL15reads_trim_paired | PairedEndLibrary | Trimmed Reads |
| LL15reads_trim_unpaired_fwd | SingleEndLibrary | Trimmed Unpaired Forward Reads |
| LL15reads_trim_unpaired_rev | SingleEndLibrary | Trimmed Unpaired Reverse Reads |

| LL15reads_trim_paired |
| LL15reads_trim_unpaired_fwd |
| LL15reads_trim_unpaired_rev |
| Created Object Name | Type | Description |
|---|---|---|
| SPAdes.Assembly | Assembly | Assembled contigs |

| Created Object Name | Type | Description |
|---|---|---|
| LL15_RASTtkGenomeAnnotation | Genome | RAST re-annotated genome |

| Created Object Name | Type | Description |
|---|---|---|
| LL15_ProkkaAnnotation | Genome | Annotated Genome |

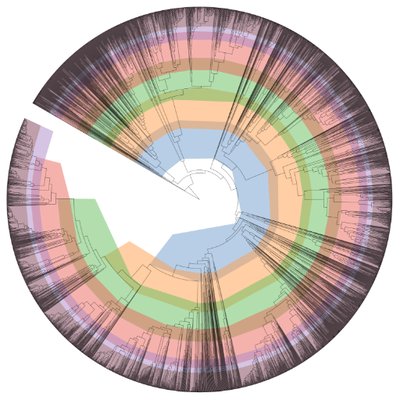

| LL15_RASTtkGenomeAnnotation |



| Created Object Name | Type | Description |
|---|---|---|
| SPAdes.Assembly_DRAM | Genome | Annotated Genome |
| Dram_Assembly | GenomeSet | LL15_Dram |