Generated December 10, 2024
Kellyn Dolezal1 and Joshua T. Cooper2 ORCID
1Department of Chemistry & Biochemisty, Northern Kentucky University and 2Department of Biological Sciences, Northern Kentucky University, 1 Nunn Drive, Highland Heights, KY 41099, USA
This narrative was used for the draft genome of a Roseomonas species Strain GC11. This genus includes 6 known species. The specimen was collected using a water grab method in Conservancy Park, a freshwater site in Belleview, KY. This species is often identified in aquatic environments and is a known pathogen to humans1. It has been reported in healthcare settings from bacteremia in the blood2 and has also been reported to be found in human catheters3. Due to the the prevelance as a human pathogen and lack of isolation in a non-human environment this strain was of particular interest4,5.
from biokbase.narrative.jobs.appmanager import AppManager
AppManager().run_app_bulk(
[{
"app_id": "kb_uploadmethods/import_fastq_noninterleaved_as_reads_from_staging",
"tag": "release",
"version": "31e93066beb421a51b9c8e44b1201aa93aea0b4e",
"params": [{
"fastq_fwd_staging_file_name": "GC11_S178_R1_001.fastq.gz",
"fastq_rev_staging_file_name": "GC11_S178_R2_001.fastq.gz",
"name": "GC11_Reads",
"sequencing_tech": "Illumina",
"single_genome": 1,
"read_orientation_outward": 0,
"insert_size_std_dev": None,
"insert_size_mean": None
}]
}],
cell_id="d04fe1dc-ddf5-4061-af52-6b3e209f6075",
run_id="4017689b-f5c1-4c08-9a1a-7cca48ca2502"
)
The KBase programs6 were used to analyze reads and assemble the genome. FastQC was used to analyze the reads and Trimmotatic was used to trim reads with Nextera adapters. The genome was determined to be 100% complete and without contamination using CheckM. In addition, RASTtk and Prokka were used for general genome annotation. However, the final annotation is provide using NCBI Prokaryotic Genome Annotation Pipeline7, and can be accessed at this Accession Number PRJNA734631. The length of the genome assembly was 5,252,435 bp with 212 contigs. The GC% content was 70.72% GC and had an N50</a> value of 53,914 bp.


| Created Object Name | Type | Description |
|---|---|---|
| GC11reads_trimmed_paired | PairedEndLibrary | Trimmed Reads |
| GC11reads_trimmed_unpaired_fwd | SingleEndLibrary | Trimmed Unpaired Forward Reads |
| GC11reads_trimmed_unpaired_rev | SingleEndLibrary | Trimmed Unpaired Reverse Reads |

| GC11reads_trimmed_paired |
| GC11reads_trimmed_unpaired_fwd |
| GC11reads_trimmed_unpaired_rev |
| Created Object Name | Type | Description |
|---|---|---|
| SPAdes.Assembly | Assembly | Assembled contigs |

| SPAdes.Assembly |
| Created Object Name | Type | Description |
|---|---|---|
| SPAdes.Assembly.RAST | Genome | Annotated genome |
| RAST | GenomeSet | Genome Set |
The RAST algorithm was applied to annotating a genome sequence comprised of 212 contigs containing 5252435 nucleotides. No initial gene calls were provided. Standard features were called using: glimmer3; prodigal. A scan was conducted for the following additional feature types: rRNA; tRNA; selenoproteins; pyrrolysoproteins; repeat regions; crispr. The genome features were functionally annotated using the following algorithm(s): Kmers V2; Kmers V1; protein similarity. In addition to the remaining original 0 coding features and 0 non-coding features, 5602 new features were called, of which 538 are non-coding. Output genome has the following feature types: Coding gene 5064 Non-coding crispr_array 1 Non-coding crispr_repeat 99 Non-coding crispr_spacer 98 Non-coding repeat 290 Non-coding rna 50 Overall, the genes have 2390 distinct functions. The genes include 2235 genes with a SEED annotation ontology across 1270 distinct SEED functions. The number of distinct functions can exceed the number of genes because some genes have multiple functions. SPAdes.Assembly succeeded!

| Created Object Name | Type | Description |
|---|---|---|
| Prokka | Genome | Annotated genome |
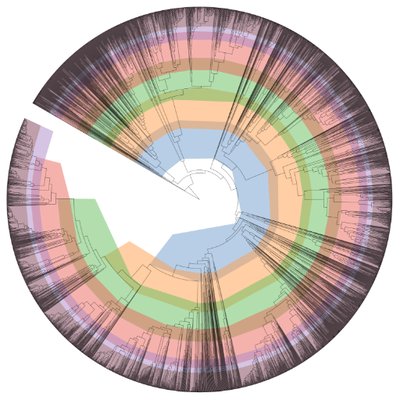
The genome was classified using GTDB-Tk as a member of the genus Roseomonas but was a distant match. The identity was additionally explored using JSpeciesWS and Type (Strain) Genome Server, TYGS. These found that the strain GC11 shared 96.36% of its genome with Roseomonas cervicalis ATCC 49947. A Kbase Species Tree and digital DNA-DNA hybridization (dDDH) from TYGS were used for classification using the d4 formulat value (dDDH) which had a value of 9.6%, demonstrating little similarity to sequecned genomes in the TYGS database. It is likely this strain is undescribed taxon within the genus Roseomonas.
DRAM was used to predict the potential metabolism of the new strain compared to other published Roesomonas genomes. DRAM analyzes based on Prokka annotations of GC11 suggest it likely has roles in degrading complex carbohydrates and a possible role in nitrite and thiosulfate reduction in lentic aqautic habitats.

| Prokka |




