Generated June 30, 2023
We report the complete genome sequence of Bradyrhizobium strain NP1, which was isolated from forest soil that had been subject to chronic warming. The diverse genus Bradyrhizobium is predicted to contain approximately 800 species (1) and includes non-symbiotic species that dominate forest soil (2). Bradyrhizobium NP1 was isolated from a Long-Term Ecological Research site in the Harvard Forest (HRF), in Petersham, MA (42.54, -72.18).
Authors: Trevor Fishera, Francesca Durmazolua, Kristen M. DeAngelisb, Maureen A. Morrowa
We report the complete genome sequence of Bradyrhizobium strain NP1. This bacterium was isolated from forest soil that had been subject to chronic warming. The genome of this novel isolated bacteria is presented as a single circular contig of 7,712,921 base pairs with 64.14% GC content.
| Table 1 | Isolation Medium |
|---|---|
| Ingredient | Amount Per Liter |
| DifcoTM Nutrient Broth | 0.08g |
| NH4NO3 | 0.50g |
| 1M CaCl | 0.60ml |
| Agar | 6.00g |
| Gellan Gum | 6.40g |
| Cyclohexamide | 50.0g |
Whole-genome sequencing (WGS) was performed using the Illumina DNA Prep kit and IDT 10bp UDI indices on an Illumina NextSeq 2000 (2x151bp reads) by SeqCenter (Pittsburgh, PA). Demultiplexing, quality control and adapter trimming was performed with the proprietary bcl-convert (v3.9.30), resulting in 7,223,840 reads. The reads were trimmed with Trimmomatic (v0.36)(4), in the DOE Systems Biology Knowledgebase (KBase) platform (5) using default parameters. The resultant 7,115,010 reads had an average read length of 145.82 ± 17.45 (134X coverage).
The same DNA sample was sequenced at Plasmidsaurus (Eugene, OR). The library was constructed with the Oxford Nanopore Technologies Ligation Sequencing Kit version SQK-LSK115 and was sequenced on GridION 10.4.1 flowcells (FLO-MIN114) using the “Super accuracy” basecaller in MinKNOW. The reads were filtered with Filtlong (v.0.2.10, https://github.com/rrwick/Filtlong) in KBase (5) to remove reads <1000 nucleotides and 5% of the lowest quality. A total of 52,003 reads were obtained (average read length, 8030.49 ± 6726.47, 54X coverage).
CheckM showed 99.98% completeness and 1.01% estimated contamination. See CheckM report
The assembled sequence was annotated with RASTtk (v1.073)(8) and is predicted to encode 7,808 proteins.

| NP1_hybrid_unicycler.contigs |


| Created Object Name | Type | Description |
|---|---|---|
| NP1_RastAnnotated | Genome | RAST re-annotated genome |
The initial classification was done by 16S rRNA alignment in BLASTn with the PCR product having a average quality score of 42.5 (4Peaks, v1.8, GenBank acession number:OR045828).
The alignment results produced a 99.6% match with at least 100 strains of Bradyrhizobium (see table). We also built species trees using KBase apps that employ a set of phylogenetic marker genes other than the 16S rRNA:GTDB-Tk and Insert Genome into Species Tree, using default parameters (see below). No species match was produced.

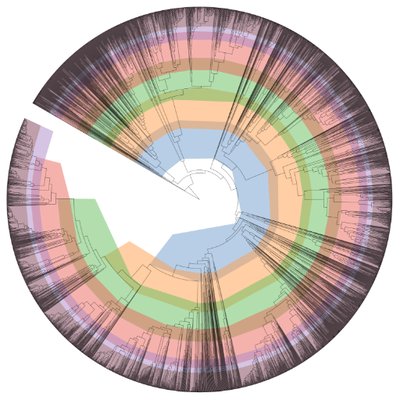
| Created Object Name | Type | Description |
|---|---|---|
| NP1_RastAnnotated | Genome | Taxonomy and taxon_assignment updated with GTDB |

| NP1_RastAnnotated |