Generated December 4, 2024
Mautusi Mitra1 ORCID and Ana Stanescu2 ORCID
1 University of West Georgia, School of Field Investigations and Experimental Sciences
2 University of West Georgia, School of Computing, Analytics, and Modeling, 1601 Maple Street, Carrollton, GA 30118, USA
We have isolated a new species of Microbacterium, an Actinobacterium. We have temporarily named this bacterium as Microbacterium sp. strain Clip185 (hereafter called strain Clip185) from a contaminated Tris-Acetate-Phosphate (TAP) medium culture plate of a green micro-alga Chlamydomonas reinhardtii strain LMJ.RY0402.185141 (a Chlamydomonas Library project CLiP strain). We sequenced the whole genome of strain Clip185 using the PacBio Sequel II Continuous Long Read technology and have submitted it to NCBI along with the SRA and PacBio methylation motif data. Additionally, we have submitted the PacBio methylome to REBASE, Ref#35996. We present the whole genome sequence of this new Microbacterium species that offers insights into its coding and non-coding genes and its nearest taxonomic neighbors.
Microbacterium, Actinobacterium, decaprenoxanthin, xenobiotics-degrader, heavy metal-tolerant
A novel species of Microbacterium strain Clip185, subsequently referred to as Clip185 in this narrative, was isolated from a contaminated Tris Acetate Phosphate (TAP) medium culture plate of Chlamydomonas reinhardtii at the University of West Georgia; Geolocation data: Carrollton, Georgia; 1,102 ft (336 m); 33.5730 N 85.1037 W (1). Strain Clip185 has one circular chromosome with a genome size of 3.3Mb. We report the complete genome sequence of Clip185 and offer insights into its genomic coding potential.
Microbacterium sp. strain Clip185 was isolated from a contaminated Tris Acetate Phosphate (TAP) medium culture plate of the green micro-alga Chlamydomonas reinhardtii strain LMJ.RY0402.18514, a Chlamydomonas Library project (CLiP) strain.
Genomic DNA was isolated from the Lysogeny Broth (LB) medium-grown Microbacterium sp. strain Clip185 (colony #37) using the Qiagen Blood and Cell Culture DNA Mini Kit.
After determination of genomic DNA purity and DNA quantification, the DNA sample was shipped to Georgia Genomics and Bioinformatics Core (GGBC) at the University of Georgia (Athens, GA). At GGBC, the sample was processed for preparation of the PacBio Single Molecule Real Time (SMRT) bell sequencing library according to the protocol given in the PacBio technical manual for template preparation and sequencing (please see QC section for more details). The SMRT bell sequencing library was barcoded and sequenced with two additional barcoded microbial SMRT Bell sequencing libraries in a single SMRT cell using PacBio SMRT Continuous Long Read sequencing on the PacBio Sequel II instrument. SMRT Link v9 was used as an interface to manage the workflow from sample setup to result analysis.
Reads were first assembled using the SMRT Link v9 software, which has inbuilt HGAP v4.0. The pipeline was run at default with a pre-specified approximately estimated genome size of 3.3Mb (based on available complete genome sizes of various Microbacterium sp. on NCBI). After assembly, the assembly metrics for each sample along with HMM predicted genes were determined by running Quast v5.02. Genome was also assembled with FLYE v2.9.1 and CANU v2.2 for statistical confidence.
The Clip185 genome consists of one circularized chromosome comprising a total of 3,305,635bp with an overall G+C content of 69.5%. Genome coverage was calculated using the formula: Number of Subread Bases (mapped)/Genome Size = 10,942,194,255/3,305,635 = 3,310X. Genome coverage (based on hgap.depth_coverage_mean in the PacBio coverage report): 3193.6X.
| GenBank | Topology | Size (bp) | GC Content (%) |
|---|---|---|---|
| CP117996.1 | Circular | 3,305,635 | 69.5 |
from biokbase.narrative.jobs.appmanager import AppManager
AppManager().run_app_batch(
[{
"app_id": "kb_uploadmethods/import_fasta_as_assembly_from_staging",
"tag": "release",
"version": "5b9346463df88a422ff5d4f4cba421679f63c73f",
"params": [{
"staging_file_subdir_path": "GCF_028743715.1_ASM2874371v1_genomic.fna",
"assembly_name": "GCF_028743715.1_ASM2874371v1_genomic.fna_assembly"
}],
"shared_params": {
"type": "draft isolate",
"min_contig_length": 500
}
}],
cell_id="ba02057d-8da4-4709-805b-35ed1caf1972",
run_id="64b02c3c-dcca-489b-a771-bee8ed06af48"
)

| Created Object Name | Type | Description |
|---|---|---|
| Clip185_Annotation_RASTtk-v1.073 | Genome | RAST re-annotated genome |

| Created Object Name | Type | Description |
|---|---|---|
| GCF_000202635.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000633215.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001262495.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001314225.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001427145.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001427525.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001428485.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001552475.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001592125.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001652465.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_001887285.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_900104345.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000746195.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| Clip185_Annotation_RASTtk-v1.073 | Genome | Taxonomy and taxon_assignment updated with GTDB |
| GCF_000799385.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000802305.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000956415.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000956465.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000956475.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000956535.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| GCF_000956575.1 | Genome | Taxonomy unchanged, taxon_assignment added GTDB |
| Clip185_Output_Genome_Set | GenomeSet | Taxonomy and taxon_assignment updated with GTDB |

| Clip185_Annotation_RASTtk-v1.073 |

| Created Object Name | Type | Description |
|---|---|---|
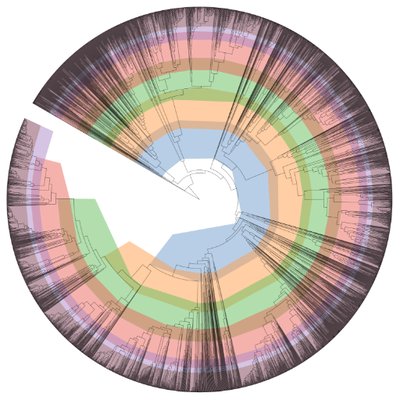
| top50_mega_muscle_msa_tree | Tree | top50_mega_muscle_msa_tree Tree |